한준수 — Backend Engineer
문제를 구조적으로 파악하고, 끝까지 책임지고 해결하려는 개발자입니다.
복잡한 요구나 모호한 상황에서도 먼저 흐름을 정리하고, 일관성 있게 풀어가는 데서 즐거움을 느낍니다. 이러한 접근은 실제로 3번의 서비스 버전업을 주도하고, 팀 내에 처음으로 아키텍처 개선을 도입할 때 큰 힘이 되었습니다. 단순히 문제를 해결하는 데 그치지 않고, 장기적으로 유지보수성과 일관성을 확보할 수 있도록 구조를 설계하고 개선해 나가는 과정에 책임감을 갖고 임하고 있습니다.
왜 이렇게 만드는지가 설명 가능한 개발을 더 중요하게 생각합니다 🙋♂️
결국 개발은 “기술로 가치를 전달”하는 일. 기술 그 자체보다 “왜 이게 고객/비즈니스에 도움이 되는가” 를 아는 것이 중요한 포인트라고 생각합니다. 근거가 명확하면 오버 테크놀로지를 경계하고, 유지보수와 확장 시점에 근거 있는 수정이 가능해집니다.
기술만큼 중요한 것은 ‘이해관계자와의 소통’입니다.
특히 개발자에게 소통은 단순히 말 잘하는 걸 넘어서, “각자 다르게 생각하고 있는 걸 조율해서, 팀의 합의된 기준으로 바꾸는 과정”이라고 생각합니다.
Working Philosophy
시스템 설계의 깊이가 AI 활용의 천장이다. 도메인 모델링·헥사고날 아키텍처·분산 트레이싱 같은 기본기가 단단할 때, LLM 페어 프로그래밍은 단순 코드 보조를 넘어 시스템 컴포넌트로 통합됩니다.
세 가지 축으로 일합니다.
1. 시스템적 사고 (Systematic Thinking)
복잡성과 모호함이 큰 문제일수록 먼저 흐름과 경계를 정의합니다. 문제 해결의 목표는 ‘동작하게 만드는 것’이 아니라 ‘시간이 지나도 일관성과 유지보수성을 잃지 않게 만드는 것’입니다.
2. 설명 가능한 의사결정 (Explainable Engineering)
모든 기술 선택에 비즈니스 근거를 명시할 수 있어야 합니다. 근거가 명확할 때만 오버 엔지니어링을 경계할 수 있고, 후일의 변경이 자의적이지 않게 됩니다.
3. 도구를 사용하는 것을 넘어, 만들어 씁니다 (Building the Tools)
좋은 도구는 좋은 결과의 전제 조건입니다. AI 시대의 개발자는 LLM의 사용자에 그치지 않고, 자신과 팀의 워크플로에 맞춘 자동화 인프라를 직접 설계·구축하여 생산성을 구조적으로 끌어올릴 수 있어야 합니다.
이 세 축의 결합으로, 보통 팀 단위로 진행되는 작업을 단독으로 짧은 기간에 안정적으로 완성합니다.
Skills
| 영역 | 기술 |
|---|---|
| 언어 | TypeScript, Java, Python, Dart |
| 백엔드 프레임워크 | NestJS, Spring Boot 3, Express, Fastify |
| 아키텍처 / 솔루션 | Microservice Architecture, Domain-Driven Design, Hexagonal Architecture, ArchUnit |
| API | REST, gRPC |
| GraphQL | Apollo Server, Apollo Federation v2 (subgraph 설계 / Schema Composition), DataLoader (N+1 해결), Custom Directive (@auth, @rateLimit 등 cross-cutting concern) |
| 데이터 | MySQL, PostgreSQL, MongoDB, Redis, OpenSearch (k-NN Vector Search) |
| 메시징 | Apache Kafka (CDC, Streams), AWS SQS / SNS, MQTT, Outbox 패턴 |
| 인프라 | AWS (ECS, Lambda, S3, CloudFront, CodePipeline), Terraform, Docker, GitHub Actions, AWS CDK |
| 관측성 | OpenTelemetry, Sentry, Grafana, Prometheus, Datadog, AWS Distro for OpenTelemetry |
| AI / 콘텐츠 | Python LangGraph, GPT-5.5, gpt-image-2, Claude Code (CLI headless 자율 에이전트), Model Context Protocol (MCP) 서버 자체 구현 |
Career
친한약사(PharmaBros)
직무 Backend Engineer (NestJS / Spring Boot / 풀스택 일부)
회사 소개 약사가 직접 답변하는 영양제·건강기능식품 큐레이션 모바일 플랫폼. 모바일 앱(iOS/Android), 웹, 약사 어드민, 공동구매 커머스를 운영하며, 사용자는 1:1 약사 상담, 영양제 보관함, 함량 분석 리포트, 공동구매 등을 이용합니다.
배경
클라이언트 측 OAuth 처리로 인한 토큰 노출 위험, 동일 사용자가 여러 채널(이메일/카카오/네이버/애플)로 가입하여 상담·보관함 데이터가 분산되는 문제, 해외 사용자 미지원, 탈퇴 직후 재가입 어뷰징 우려가 동시에 존재했습니다. 단순 신규 기능이 아니라 이미 운영 중인 사용자 베이스를 무중단으로 새 시스템에 옮겨야 하는 마이그레이션 작업이었습니다.
가설
본인인증 기반 동일인 식별 + OAuth 서버 측 이관 + 신·구 시스템 호환 레이어를 함께 가져가면, 사용자 가입/로그인 실패 없이 무중단으로 전환할 수 있다.
진행 과정
- OAuth 인증을 클라이언트 측에서 서버 측으로 전면 이관, JWT를 URL에 노출하지 않고 단기 캐시 + 단방향 hash 기반 안전한 리다이렉트 플로우 설계
- 본인인증 기반 동일인 자동 식별 + 다중 계정 통합 모듈 신설 — 상담·보관함·소셜 계정 등 도메인 데이터 마이그레이션 포함
- 순환 의존성 해결을 위한 Facade 패턴 도입으로 인증·회원 모듈 경계 정리
- 분산 락으로 동시 인증 요청 충돌 방어, 트랜잭션 원자성 보장
- 탈퇴 후 일정 기간 동일 본인인증 기반 재가입 차단 정책 구현
- 신·구 시스템 점진 전환 호환성 레이어 (fallback + auto-migration) 설계 — 양 시스템 혼용 기간 동안 V1 가입 사용자가 V5 로그인 실패하지 않도록 자동 마이그레이션
- 해외 사용자 대응 (국가 코드 기반 분기, 국제 전화번호 표준화)
결과
인증 보안 위험 제거, 다중 계정 사용자 데이터 일관성 회복, 무중단 전환 기간 동안 사용자 가입 실패율 0건 유지, 해외 사용자 가입 가능. 호환성 레이어로 인해 신규 시스템 출시 일정이 앱 스토어 심사 일정에 종속되지 않게 됨.
배경
SNS(인스타그램 카드뉴스, X 트윗, 공동구매 캘린더, 멀티링크 페이지) 콘텐츠 수동 제작 비용이 과다했고, 한편으로는 사내에 누적된 약 9.4만 건의 약사 상담 데이터라는 큰 자산이 콘텐츠 큐레이션에 활용되지 못하고 있었습니다. 사내에 LLM 파이프라인 사례가 없는 상태에서 0 → 1 신규 구축이 필요했습니다.
가설
LangGraph 기반 노드형 파이프라인 + RAG 기반 주제 큐레이션 + LLM 4축 자동 평가 루프 + 채널별 전략 분리를 결합하면, 사람이 디자인-카피-검수를 거치는 단계를 자동화하면서도 사람 검수 시점의 품질 기대선을 유지할 수 있다. 단순 LLM 호출이 아니라 자체 데이터로 학습된 콘텐츠가 차별화의 핵심이 된다.
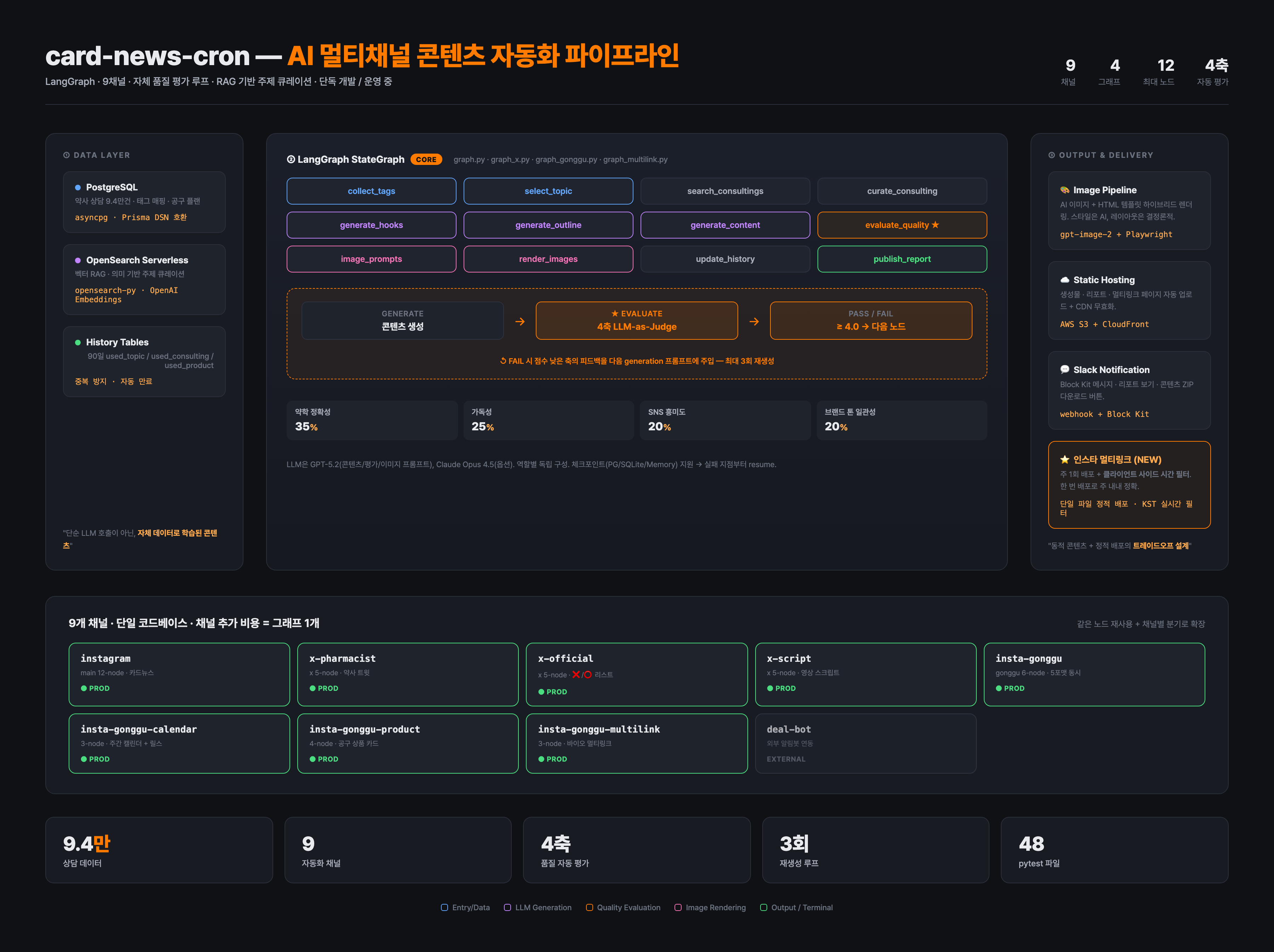
진행 과정
- 9개 채널 파이프라인 단독 설계 — instagram(메인 12노드), x-pharmacist / x-official / x-script(각 5노드), insta-gonggu(5포맷 동시), insta-gonggu-calendar(주간 캘린더 + 릴스), insta-gonggu-product(공구 상품 카드), insta-gonggu-multilink(바이오 멀티링크), deal-bot(외부 알림봇 연동). 단일 코드베이스에서 같은 노드를 재사용 + 채널별로 분기 — 채널 추가 비용 = 그래프 1개
- RAG 기반 주제 큐레이션 — OpenSearch Serverless + OpenAI Embeddings로 9.4만 건 상담을 의미 검색하여 채널 톤에 맞는 주제 선정. 90일 사용 이력(used_topic / used_consulting / used_product) 테이블로 중복 방지 + 자동 만료
- 12 노드 LangGraph StateGraph —
collect_tags → select_topic → search_consultings → curate_consulting → generate_hooks → generate_outline → generate_content → evaluate_quality → image_prompts → render_images → update_history → publish_report. 체크포인트(PG/SQLite/Memory) 지원으로 실패 지점부터 resume 가능 - LLM-as-Judge 4축 자동 평가 + 재생성 루프 — 약학 정확성 35% / 가독성 25% / SNS 흥미도 20% / 브랜드 톤 일관성 20% 가중 평균. ≥ 4.0 통과, FAIL 시 점수 낮은 축의 피드백을 다음 generation 프롬프트에 주입 — 최대 3회 재생성
- 이미지 파이프라인 — AI 이미지(gpt-image-1 / 1.5) + HTML 템플릿(Playwright) 하이브리드 렌더링. 스타일은 AI, 레이아웃은 결정론적
- 컴플라이언스(의료법) 워딩 규칙을 시스템 프롬프트와 후처리 양쪽에 적용 — 의료/상담 관련 단어 대체 표현 가이드
- 인스타 멀티링크 — 클라이언트 사이드 시간 필터: 주 1회 S3 배포 + HTML에 전체 공구 데이터 인라인, 클라이언트 JS가 KST 기준으로 실시간 필터 → 단일 파일 정적 배포로 주 내내 정확 (“동적 콘텐츠 + 정적 배포의 트레이드오프 설계”)
- 운영 도구 일체 — AWS S3 + CloudFront 자동 배포 + 무효화, Slack 알림(Block Kit · 리포트 보기 · 콘텐츠 ZIP 다운로드 버튼), GitHub Pages 비교 리포트
- 48개 pytest 파일로 노드 단위 회귀 방지
결과
9개 채널 동시 운영을 단독으로 유지·확장 가능. 매주 수동으로 진행하던 콘텐츠 업데이트 작업이 자동화됐고, 4축 자동 평가로 사람 검수 비용을 구조적으로 낮췄으며, 채널 추가 비용이 “그래프 1개”로 압축되어 신규 채널 출시 사이클이 단축됐습니다.
배경
단일 에러 모니터링 도구(Sentry)만으로는 분산 트레이싱·메트릭 수집에 한계가 있었습니다. DB 쿼리·로그·에러를 단일 traceId로 묶어 보지 못해, 운영 중 발생한 장애가 어느 요청 흐름에서 시작됐는지 추적하는 데 시간이 길어지고 있었습니다.
가설
OpenTelemetry 표준 + 기존 Sentry와의 traceId 공유 + 자동 인스트루멘테이션을 결합하면, 도메인 코드를 거의 손대지 않고도 모든 요청·DB 쿼리·로그에 traceId를 자동으로 붙일 수 있다.
진행 과정
- OpenTelemetry SDK를 사내 공통 라이브러리로 추상화, 환경 변수 한 줄로 활성/비활성 토글 가능
- Sentry의 traceId 전파자(Propagator)와 OTel SDK를 통합하여 traceId 단일화 — 에러 ↔ 트레이스 ↔ 메트릭 상관 분석 가능
- ORM(Prisma)과 로그 라이브러리(Winston)에 자동 인스트루멘테이션 적용 → DB 쿼리·로그에 traceId 자동 주입
- AWS ECS 환경에 사이드카(Sidecar) 배포 구성을 운영 환경 한정으로 점진 적용 (안전 우선)
- 로컬 개발용 모니터링 스택(OTel Collector + Prometheus + Grafana)을 컨테이너로 패키징하여 팀원이 즉시 사용 가능하도록 제공
- Grafana 대시보드 25개 패널 프로비저닝 (RPS, 에러율, P50/P95/P99 응답시간, Node.js 런타임 메트릭, Prisma DB 메트릭)
결과
에러 진단 시간 단축, ORM 슬로우 쿼리 가시화, 운영 환경 안정성 개선. 한 번 깔린 인프라 위에 추후 메트릭/트레이스를 추가하는 데 코드 수정이 거의 필요 없어짐.
배경
사용자 참여가 일방향 소비(보관함, 상담)에 그치고 있었고, 친한약사의 차별화 포인트(약사 큐레이션 + 데이터 기반 영양제 분석)를 사용자에게 직접 보여줄 기능이 빈약했습니다. 두 영역(상호작용 + 데이터 인사이트)을 동시에 채워야 했습니다.
가설
댓글·좋아요·신고를 정규화된 도메인으로 새로 짜고 비회원 조회를 열면 SEO 유입 + 사용자 활성화를 동시에 잡을 수 있고, 영양 성분 함량을 일일 섭취 기준으로 환산하면 단순 통계가 아닌 개인화된 비교 기준(상위 N%, 일일 권장 대비)을 제시할 수 있다.
진행 과정
커뮤니티 도메인
- 댓글 / 답글 / 좋아요 / 신고 도메인 신설 — DDL 정규화, check constraint, enum 기반 신고 사유
- 커서 기반 페이지네이션 — offset 방식 한계 회피
- 비회원 조회 가능 + 비동기 이벤트 속도 개선 — SEO 유입 대응
- 사용자 랭킹 — 가장 많이 좋아요/댓글 단 유저 조회
- CRM 연동 — 답글 생성 이벤트로 외부 CRM 알림
건강 기능
- 영양 성분 함량 분석 — 이벤트 기반 트리거, 1회 섭취 × 일일 횟수 환산, 단위 변환 케이스(mg/μg)
- 건강 활동 집계 배치 — 보관함·상담 활동 일일 집계, 상위 percentile 응답
- 건강 고민 큐레이션 — 사용자 건강 고민에 맞는 영양제 함량 분석 케이스 매핑
- 콘텐츠 메타데이터를 외부 SaaS(Airtable)로 이관 — 비개발자(콘텐츠 운영팀) 직접 운영
결과
사용자 상호작용 도메인 구축, 비회원 SEO 유입 채널 확보, 차별화 가능한 데이터 기반 기능 출시, 콘텐츠 운영의 개발자 종속 제거.
배경
Flutter native로 작성된 한 줄 상담 작성/완료 페이지의 디자인을 바꿀 때마다 앱 스토어 배포가 필요했습니다. 디자인 iteration 주기가 출시 사이클에 묶여 있었습니다.
가설
자주 바뀌는 페이지(작성·완료)만 WebView로 빼고 native UX 디테일(swipe back, 미저장 콘텐츠 보호)은 native ↔ web 약속된 인터페이스로 처리하면, native 동등성을 잃지 않고도 디자인 자유도를 확보할 수 있다.
진행 과정
- 한 줄 상담 작성·완료 페이지를 React 웹뷰로 전환, 수정 모드는 Flutter 유지 (점진 전환)
- swipe back / 브라우저 뒤로가기 인터셉트 패턴 설계 — 미저장 콘텐츠 보호 모달을 웹에서 노출하고 native가 그 결정에 따르는 구조
- 딥링크 라우팅 정합성 개선 (앱 ↔ 웹 경로 매핑)
- 알림 모달 파라미터 등 동적 진입점 지원
결과
디자인 iteration이 앱 배포에서 분리되어 출시 주기 단축, 웹/앱 UX 일관성 확보.
배경
모놀리식 NestJS 백엔드가 비대해져, 일부 도메인 변경에도 전체 빌드/배포가 필요했고, 공통 유틸이 도메인 디렉토리마다 흩어져 있었습니다.
가설
워크스페이스 기반 모노레포 + 공통 라이브러리 분리 + 앱 단위 독립 배포로 전환하면, 변경의 격리와 빌드 시간 단축을 동시에 얻을 수 있다.
진행 과정
- 모놀리식 NestJS 코드를 모노레포 워크스페이스 구조로 전환, 앱 단위 독립 배포 가능 구조 설계
- 공통 인프라(텔레메트리, AWS 통합, 유틸)를 공유 라이브러리로 분리
- CI/CD 파이프라인 정비 — 자체 호스팅 러너, 캐시 최적화, 환경 변수 관리, ECR 단계 정비
결과
빌드/배포 단위 분리로 운영 효율성 개선, 공통 코드 재사용성 향상, 앱별 독립 배포 가능.
오누이 (설탭)
직무 Backend Engineer (NestJS / Spring Boot) 도메인 학습 플랫폼 — 강사-학생 매칭, 콘텐츠, 교재 시스템, 사내 아키텍처 표준화
회사 소개 비대면 화상 과외 매칭 플랫폼 ‘설탭’을 운영하는 에듀테크 스타트업. 강사-학생 매칭, 학습 콘텐츠, 교재 시스템 등을 모바일 앱과 웹으로 제공합니다.
배경
기존 강사-학생 매칭은 조건이 복잡해지면서 조회 속도가 느려졌고, 선생님 도메인과 매칭 도메인이 한 데이터 소스에 묶여 있어 도메인 분리도 필요했습니다. 신규 서비스 런칭(설탭 3.0) 시점에 매칭 알고리즘 고도화 + 어드민 기능까지 동시에 요구되었습니다.
가설
매칭에 필요한 데이터를 선생님 도메인에서 별도 데이터 파이프라인으로 추출하고, MongoDB의 복합 인덱싱 + Aggregation을 활용하면 검색 속도 개선과 도메인 분리를 동시에 달성할 수 있다.
진행 과정
- 14가지 매칭 조건(전공, 경력, 성격, 수업 가능 시간 등)을 적용한 추천 알고리즘 설계
- MongoDB 복합 인덱싱 + Aggregation 기반 검색 (Mongo Search) 활용
- CDC(Change Data Capture) 기반 데이터 파이프라인 구축 — 타 도메인(프로필, 일정, 리뷰)의 데이터를 매칭 도메인에 비동기 반영
- 관리자용 어드민 페이지 — 매칭 결과 검토, 수동 수정, 강사 배정
- Redis Key Expiration Event를 통한 내부 스케줄링 구현
- Outbox Pattern으로 비동기 메시지 신뢰성 확보
결과
기존 시스템 대비 약 70% 검색 속도 향상, 매칭 도메인 독립 배포 가능, 관리자 매칭 개입 자동화.
배경
학습 콘텐츠를 모든 유저에게 동일하게 노출하던 방식은 한계가 명확했습니다. 유저별로 이해도·진도·약점이 다르고, 콘텐츠 양이 늘어나면서 “어떤 콘텐츠를 누구에게 보여줄지”가 핵심 문제로 떠올랐습니다. Knowledge Tracing(학습자 지식 상태 추적) 모델을 적용하려면 기존 학습 이력 데이터 구조부터 재정비가 필요했습니다.
가설
학습 이력 데이터를 KT 모델이 사용 가능한 시퀀스 형태로 마이그레이션하고, 콘텐츠에 유형/개념 태그를 부여하면, 유저별 약점을 추정해 다음 콘텐츠를 자동 추천할 수 있다.
진행 과정
- Knowledge Tracing 모델 적용을 위한 학습 데이터 파이프라인 설계 및 구조 마이그레이션 — 기존 학습 이력을 KT 모델 입력 형식(시퀀스 단위 시간·맥락·문항 정합성)에 맞게 재구성
- 콘텐츠별 유형/개념 자동·수동 태깅 시스템 구현 — LLM/룰 기반 자동 태깅으로 1차 커버 + 운영자 검수 워크플로
- 유저 학습 이력 기반 콘텐츠 자동 추천 기능 개발 — KT 모델이 추정한 유저 지식 상태 + 콘텐츠 태그 매칭으로 다음 학습 콘텐츠 자동 추천
결과
개인화 추천 기반 학습 경험 도입, 콘텐츠 활용도 향상, 운영자가 직접 추천 룰을 관리할 필요 없는 자동화 인프라 확보.
배경
기존 교재 업로드는 script 기반이라 휴먼 에러가 빈번하고, 등록 결과를 명시적으로 확인할 수 없었습니다. 발행 시점도 관리자가 통제할 수 없었고, 메타데이터 부재로 검색·데이터 분석이 불가능했습니다. 약 6백만 건의 교재 데이터 + 9백만 건의 사용자 필기 데이터를 운영 중인 시스템에서 무중단으로 마이그레이션해야 했습니다.
가설
교재 데이터(전처리 필요)와 필기 데이터(실시간 생성·수정·유실 불가)는 제약이 다르므로, Kafka CDC + Dual Write + 점진적 read 비율 전환을 결합하면 데이터 유실 없이 cutover 할 수 있다. DFS / Dynamic Programming 알고리즘으로 데이터 중복 제거와 관계 재구성을 최적화할 수 있다.
진행 과정
- 신규 서비스와 기존 서비스에 dual write 적용
- old DB binlog에 CDC 연결, Kafka Streams에서 검증 로직 구현
- read 비율 점진 조정으로 cutover 진행
- 교재 데이터 DFS / Dynamic Programming 기반 중복 제거 + 관계 재구성
- 새 데이터 구조 전처리 + 메타데이터 부여 (검색·분석 지원)
- 어드민 시스템 구축 — 등록 결과 명시적 확인, 발행 시점 통제
결과
6M + 9M 데이터를 무중단으로 신규 시스템으로 이관, 운영 휴먼 에러 제거, 검색·분석 가능 메타데이터 확보.
배경
자체 제작 교재만으로는 콘텐츠 다양성에 한계가 있었습니다. 외부 출판사 계약 교재를 우리 학습 플랫폼에 통합하는 신규 비즈니스 모델 “설탭 북스” 출시가 결정됐고, 단순 교재 등록을 넘어 구매·등록·학습·정산까지 묶인 멀티 도메인 시스템이 필요했습니다. 출판사는 매출 가시성·정확성을 요구하고, 자사는 기존 학습 경험과의 통합을 유지해야 하는 두 축의 요구가 동시에 존재했습니다.
가설
- 구매 → 등록(Entitlement) → 학습 → 정산까지를 단일 책임으로 모듈화하고, 기존 학습 도메인과는 gRPC 경계로만 통신하면, 신규 비즈니스 모델을 기존 시스템 영향 최소화로 도입할 수 있다.
- 정산은 거래 원장(immutable ledger) 기반으로 다루어야 출판사 감사·재계산·분쟁에 항상 대응 가능하다. 정산 금액을 update하는 순간 회계 신뢰는 무너진다.
진행 과정
- End-to-End 도메인 설계 — Order(구매) / Entitlement(권한) / Study Session(학습) / Settlement(정산) 4개 Bounded Context로 분리. Outbox 패턴으로 단계 간 상태 전이의 트랜잭션 원자성 보장
- 기존 학습 도메인과 gRPC 경계 — Protobuf로 계약 명시 + 버전 호환성 유지. 출판사 교재의 학습 데이터를 기존 학습 이력에 통합 처리하면서, 신규 시스템 장애가 기존 학습으로 전파되지 않도록 격리
- 정산 모듈 — 거래 원장(Event-Sourced Ledger) 기반 설계 — 모든 정산 이벤트(매출 발생 / 환불 / 보정 / 프로모션 차감)를 append-only로 누적. 어느 시점의 상태든 원장 재생(replay)으로 재구성 가능, 감사 가능(auditable)
- 출판사별 수익 배분 룰을 데이터로 추상화 — 고정 비율 / 누진 / 프로모션 적용 / 환불 차감을 룰 엔진에서 처리. 출판사 추가·정책 변경이 코드 수정 없이 가능한 구조
- 월별 마감 스냅샷 + 자동 검증 — 매월 마감 시 거래 원장 → 출판사별 매출/수수료/환불/순지급액 자동 산출 → CSV/PDF 리포트 발행. 마감 전 합계 일치 검증(구매 합계 = 정산 합계 ± 수수료) 자동 실행, 불일치 시 자동 알림
결과
신규 비즈니스 모델 “설탭 북스” 백엔드 책임자로 기획 단계부터 출시까지 단독 진행. 출판사 정산 자동화로 매월 수동 정산 작업 제거, 출판사 감사·분쟁 요청에 거래 원장 기반으로 즉시 대응. 기존 학습 도메인에 대한 영향 0건으로 신규 비즈니스 안전 도입.
배경
기존 단순 이미지 기반 콘텐츠로는 양질의 교육 경험을 제공하기 어려웠습니다. 이미지 + 영상 + 해설 등 복합 콘텐츠를 위한 자료 구조 설계와, 등록을 위한 어드민·유저 서비스 구축이 필요했습니다.
가설
Graph 구조 데이터를 그대로 조회하면 비효율적이지만, Closure Table을 별도로 구축하면 조회 성능을 대폭 개선할 수 있다. 또한 읽기 중심 워크로드는 별도 캐시 레이어로 latency를 최소화할 수 있다.
진행 과정
- 복합 콘텐츠(이미지/영상/해설) 자료 구조 설계
- Closure Table 별도 생성으로 Graph 구조 조회 최적화
- 별도 캐시 레이어 도입 — 읽기 중심 워크로드 대응
- Circuit Breaker 적용 — 온프레미스 Redis 다운 시 반복 재시도로 인한 latency 폭증 방지
- 어드민 + 유저 서비스 구축
결과
Graph 구조 조회 대비 약 40배 조회 속도 향상, 복합 콘텐츠 등록·조회 시스템 출시, Redis 장애 시 시스템 안정성 확보.
배경
모놀리식 레거시 시스템의 운용이 점점 복잡해지고, 서비스가 커지면서 도메인별 책임 분리가 필요했습니다. 단순히 코드를 쪼개는 것을 넘어, 팀 전체의 운영 표준을 만드는 작업이 필요했습니다.
가설
Hexagonal + DDD 아키텍처 템플릿을 NestJS / Spring Boot 양쪽에 제공하고, 공통 라이브러리·CI/CD 파이프라인을 코드화하여 배포하면, 팀 차원에서 일관된 운영 표준을 만들 수 있다. NestJS의 부족한 기능(Transaction)은 ALS 기반 Custom Decorator로 보완 가능하다.
진행 과정
- Hexagonal + DDD 아키텍처 템플릿 구현 — NestJS / Spring Boot 양쪽 제공
- 공통 라이브러리 패키지 (Error Filter, Log Filter, Security 등) 템플릿과 함께 제공
- 도메인별 Datadog Sidecar 배치 — 도메인 간 흐름 추적, 에러 신속 대응
- GitHub Action CI/CD 파이프라인 코드화 — 팀 전체 일관 배포
- NestJS 미지원 Transaction을 위한 ALS(Async Local Storage) 기반 Custom Transaction Decorator 제공
- API Gateway + Apollo Federation v2 — 클라이언트-서버 종속성 제거, 단일 엔드포인트 + cross-domain 통신. Subgraph는 도메인(=팀) 단위로 분리하여 각 팀이 자기 스키마를 독립 배포
- DataLoader 패턴 컨벤션화 — 모든 resolver가 DataLoader를 거치도록 강제하여 N+1 쿼리 폭주 방지, 요청 단위 batch + cache
- Custom Directive 표준화 —
@auth,@rateLimit같은 cross-cutting concern을 스키마 레벨에서 선언적으로 처리하여 도메인 코드 오염 방지 - 서버 간 통신 규격화
결과
팀 전체 운영 표준화, 도메인별 독립 배포·모니터링, 클라이언트 단일 엔드포인트.
배경
기존 인프라 관리는 휴먼 에러 발생 확률이 높았습니다. AWS에 출처를 알 수 없는 리소스가 만 개 단위로 누적되어 있었고, 기존 리소스를 신뢰하지 못하는 개발자들이 계속 새 리소스를 생성해 일부는 limit에 도달했습니다.
가설
IaC(Terraform)으로 모든 리소스를 코드화하고 공통 모듈을 별도로 두면, 새 리소스의 무분별한 생성을 구조적으로 차단할 수 있다.
진행 과정
- Terraform으로 모든 백엔드 리소스 코드화 — 일관된 형태로 서빙
- 공통 모듈 분리 — 공통적으로 사용 가능한 부분은 새 리소스 생성 지양
- 기존 리소스의 출처·소유권 정리
결과
AWS 리소스 limit 문제 해결, 인프라 관리 일관성 확보, 휴먼 에러 감소.
머케인
직무 Backend Engineer (IoT / 공유 모빌리티) 도메인 IoT 기반 공유 모빌리티 — 신규 서비스 런칭, 디바이스 통신 인프라, 면허 검증, 분실·고장 모니터링
회사 소개 공유 킥보드 등 IoT 기반 공유 모빌리티 서비스를 운영한 스타트업. 디바이스(MQTT) 통신, GeoJSON 기반 권역 관리, 면허 검증, 분실·고장 자동 감지 등 무인 운영 시스템을 운영했습니다.
배경
신규 공유 모빌리티 서비스 ‘시티플라이’를 기획 초기 단계부터 런칭까지 백엔드 책임자로 참여했습니다. 기존 ‘머케인 메이트’ 플랫폼의 유저 데이터를 연동하여 기존 회원이 신규 서비스에서도 연속적으로 사용할 수 있어야 했습니다.
가설
MQTT 통신을 AWS SNS + SQS(fan out) 방식으로 추상화하면 도메인 간 결합성을 제거하면서 fault tolerance를 확보할 수 있다. GeoJSON 기반 권역 설정으로 권역별 관리자 제어를 동적으로 분리할 수 있다.
진행 과정
- MQTT 통신 → AWS SNS + SQS(fan out) MQ 구현 — 도메인 간 결합성 제거 + fault tolerance 확보
- 스쿠터 원격 조작 (잠금/해제 등)
- 정산 내역 확인 및 조정 기능
- GeoJSON 데이터 기반 권역 설정 + 관리 권한 분리 — 권역별 관리자 제어 권한 할당
- 기존 플랫폼 유저 데이터 연동 — 유저 변환 모듈 개발
- 관리자 백오피스 구축
결과
신규 공유 모빌리티 서비스 무중단 런칭, 도메인 간 fault tolerance 확보, 권역별 운영 자율성 보장.
배경
도로교통법 개정으로 면허증 검증 요건이 강화되었습니다. 기존 휴먼 리소스로 확인하던 프로세스는 휴먼 에러와 시간 소요가 컸고, 면허 종류·발급일·갱신 여부 등 복수 항목의 자동 검증으로 확장이 필요했습니다.
가설
AWS Textract + Tesseract-OCR 조합으로 면허증 텍스트를 추출하고, 패턴 매칭·정규표현식으로 검증 로직을 구성하면 휴먼 에러 없이 자동 검증할 수 있다.
진행 과정
- 면허증 사진 기반 OCR 도입 (AWS Textract + Tesseract-OCR)
- 면허증 주요 텍스트(이름, 면허 번호, 발급일 등) 추출
- 패턴 매칭 + 정규표현식 검증 로직 구성 — 허위 입력 방지 + 자동 데이터 정합성 검증
결과
사용자 인증 시간 평균 약 90% 단축, 휴먼 에러 제거, 도로교통법 개정 요건 자동 대응.
배경
IoT 서비스 초기에는 국내 통신사 MQTT 모듈이 불안정해서, 기기가 위수지역(지정 운행 지역)을 벗어나거나 통신 음영 지역에 진입하면 위치를 파악하지 못하는 케이스가 빈번했습니다. 분실·도난 방지가 비즈니스 핵심 리스크였습니다.
가설
상태 이상 이벤트(이탈, 통신 불량 등)를 실시간 감지하고 수거 요청으로 자동 연계하면 분실률을 낮출 수 있다. 마지막 주행 경로를 시각화하면 가맹점주의 수거 작업이 더 효율적으로 진행된다.
진행 과정
- 실시간 모니터링 시스템 설계 — 상태 이상 이벤트 감지 (위수지역 이탈, 통신 불량)
- 수거 요청 자동 연계 시스템
- 관리자 / 가맹점주용 웹 어드민 — 수거 대상 기기의 마지막 주행 경로 시각화
- 현장 운영팀·가맹점주 피드백 기반 UI/UX 반복 개선
결과
수거 요청 처리 시간 약 40% 단축, 분실·고장 기기 수거율 약 25% 향상.
배경
공유 모빌리티 기기에서 전송하는 메시지 처리를 위한 인프라가 필요했고, 기존 배포 방식은 휴먼 에러가 발생할 확률이 높아 자동화가 시급했습니다.
가설
MQTT → AWS SNS + SQS(fan out) MQ로 도메인 결합성을 제거하고 fault tolerance를 확보하며, AWS CodePipeline + GitHub Actions 기반 CI/CD로 배포 자동화 + 테스트 효율을 동시에 개선할 수 있다.
진행 과정
- MQTT 통신을 AWS SNS + SQS(fan out) MQ로 구현 — 도메인 간 결합성 제거 + fault tolerance 확보
- AWS CodePipeline + GitHub Actions CI/CD 파이프라인 도입 — 배포 자동화 + 테스트 효율
- 인프라 모니터링·로그 통합
결과
인프라 개선 이후 장애 발생률 감소 + 기능 배포 주기 단축, 운영 효율성·안정성 동시 향상.
Side Projects — “AI 워크플로 인프라” 시리즈
단발성 아이디어가 아니라, AI 도구를 운영 가능한 인프라로 통합하는 일관된 관심사의 결과물입니다.
- Reins — AI 디버깅 시 자동 컨텍스트 수집 (운영 환경)
- Wiki — AI 개발 시 자동 컨텍스트 보존 (장기 기억)
- Multi-agent 프레임워크 — 여러 LLM 에이전트의 협업 오케스트레이션
배경
디버깅에서 가장 시간이 많이 드는 건 코드 수정이 아니라 “컨텍스트 수집” 단계입니다. AI 코딩 도구의 진짜 가치는 코드 생성보다 컨텍스트 수집에 있다고 보고, 이를 인프라 레벨로 끌어올리는 실험을 직접 해보고 싶었습니다.
가설
AI 에이전트에게 충분한 도구(코드 검색, 에러 상세, 로그, DB 읽기, 배포 이력)와 안전한 실행 환경만 주면, 사람의 디버깅 첫 30분을 자동화할 수 있다.
진행 과정
- Sentry → Webhook → 인메모리 큐 → CLI 자율 실행 → 결과 파싱 → GitHub Issue + Slack 발행 파이프라인 설계
- MCP(Model Context Protocol) 서버 4종 자체 구현 — Sentry / CloudWatch Logs / DB(읽기 전용 트랜잭션 강제) / 배포 이력
- HMAC 기반 타이밍 세이프 웹훅 검증, 인메모리 큐(동시 실행 제한, 프로젝트별 쿨다운)
- LLM CLI를 헤드리스 + 예산 상한 + 비세션 모드로 실행, 출력은 Zod 스키마로 강제 검증
- 출력 발행 채널(GitHub Issue / Slack)은 독립 실패 처리 — 한쪽 장애가 다른 쪽을 차단하지 않음
- 단위 + 통합 테스트 60건 작성, 아키텍처/보안 리뷰 통과
결과
60건 테스트 통과 + 아키텍처/보안 리뷰 완료 상태로 구동 가능. AI 도구를 단순 사용자가 아닌 운영 가능한 시스템 컴포넌트로 통합하는 패턴을 직접 검증.
배경
Claude Code 같은 LLM 도구는 세션이 끝나면 의사결정·트러블슈팅 맥락을 잃습니다. AI 시대의 새로운 병목은 “코드 생성 속도”가 아니라 “맥락 복원 비용” 이라고 봤습니다.
가설
자동 기록 트리거 + 표준화된 메타데이터 + MCP 도구화를 결합하면, LLM이 사용자 지시 없이 자율적으로 장기 기억을 관리할 수 있다.
진행 과정
- 자동 기록 트리거 5종 정의 — 기술 의사결정 / 트러블슈팅 / 아키텍처 변경 / 학습 / 프로젝트 횡단(cross-cutting)
- 자동 참조 규칙 — 세션 시작 시 인덱스 + 프로젝트 메인 페이지 자동 로드
- 표준화된 frontmatter (type / project / date / tags) 강제 — 검색 가능성 보장
- Obsidian 호환 wikilink + 그래프 가독성 규칙
- Cross-cutting 자동 분류 — 여러 프로젝트에 걸치는 패턴 별도 디렉토리 승격
- MCP 서버 구현 — LLM이 위키 read/write를 1급 도구로 사용 가능
결과
다른 프로젝트로 넘어가도 즉시 맥락 복원, 동일 패턴 재발견 비용 제거, 시간이 지날수록 자산이 누적되는 복리 효과 인프라 확보.
배경
단일 LLM 호출로는 풀기 어려운 작업을 여러 역할의 에이전트가 협업하는 형태로 풀 수 있을지, 사내 도입 가능성을 직접 코드로 검증할 필요가 있었습니다.
가설
역할 기반 시스템 프롬프트(Architect / Executor / Critic 등)를 가진 에이전트들을 수렴(convergence) 엔진으로 묶고, 병리(pathology) 감지(같은 피드백 반복, 진동)를 추가하면, 무한 루프 없이 안정적으로 결과에 도달할 수 있다.
진행 과정
- 역할 기반 BaseAgent 설계 (Claude Agent SDK 기반)
- Ouroboros 수렴 엔진 + 병리 감지 (oscillation, repetitive feedback)
- Slack WorkspaceManager — 동적 채널 생성 + 에이전트 메시지 라우팅
- Express HTTP API + Docker Compose + E2E 통합 테스트
- Socratic Interview phase — 모호성 분석을 오케스트레이션 앞에 배치
결과
멀티 에이전트 협업의 실용 가능성과 한계를 직접 검증, 사내 개발 도구 도입 논의의 근거 자료 확보.
Education
인천대학교 / 경영학 학사 졸업 2010.03 ~ 2019.08
마치며
시스템 설계 안목과 LLM 기반 페어 프로그래밍을 결합해 단독으로 큰 시스템을 빠르게 만들어내는 풀스택 엔지니어입니다. 코드를 잘 쓰는 것에 그치지 않고, AI 워크플로 자체를 인프라로 설계해 본인의 생산성과 팀의 디버깅·콘텐츠 운영 작업을 구조적으로 자동화합니다.